В России искусственный интеллект найдет главные слова в древних рукописях
В МГУ разработали алгоритм, который находит нужные слова в сканах рукописей, не переводя их в машинный текст
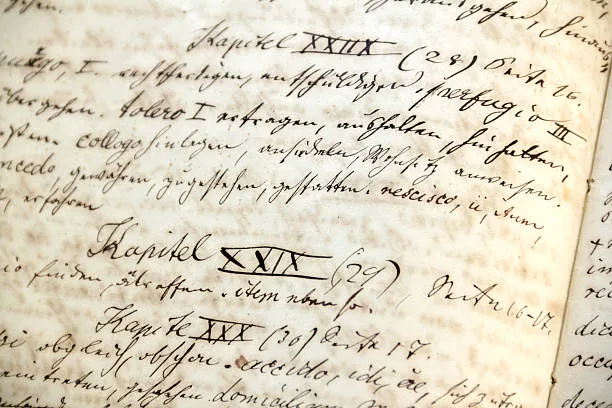
В России на факультете вычислительной математики и кибернетики МГУ предложили способ поиска по рукописным документам с помощью анализа изображений. Алгоритм обрабатывает сканы и фотографии и находит заданные слова и фразы прямо в исходнике, без перекодирования скана в текст.
В основе метода лежит разбор письма на отдельные штрихи. Система выделяет их, приводит к единому виду и классифицирует по форме. После этого она сопоставляет последовательности штрихов в запросе и в документе и находит совпадения.
Важно для архивов
Автоматическое распознавание почерка по-прежнему дает сбои, особенно при работе со старыми документами. При этом ценность рукописей часто связана не только с текстом, но и с тем, как он написан и расположен на странице.
Новый подход позволяет работать с изображением как с данными, сохраняя их визуальные особенности. Это важно для архивов, библиотек и музейных коллекций, то есть там, где требуется сохранить первоначальный вид документов.
Результаты экспериментов
Авторы протестировали алгоритм на реальных рукописях. Система уверенно нашла главные слова и сумела ранжировать результаты по степени совпадения с запросом. Все это позволяет быстрее ориентироваться в больших массивах рукописей и находить нужные фрагменты без просмотра текстов человеком.
Цифровой архивариус
Разработка может лечь в основу поисковых систем для архивов и библиотек. Также она пригодится в проектах, связанных с изучением культурного и научного наследия. Дальнейшая работа будет связана с расширением наборов данных и адаптацией алгоритма под разные стили письма.