Code That Writes Itself: How a Russian Development Is Changing the Rules of the AI Game
Russian researchers have developed and released an open-source artificial intelligence system that automatically generates and optimizes GPU kernels – specialized code executed on graphics processors. The solution is designed to accelerate and reduce the cost of neural network development.

A persistent challenge in global AI development is that up to 80% of engineering time is spent not on new ideas but on the painstaking optimization of code for graphics hardware. Researchers at the Artificial Intelligence Research Institute AIRI have addressed this bottleneck with a framework called KernelEvo. The system automatically generates and optimizes GPU kernels – specialized code used to run computations on graphics processors.
Building advanced AI systems and deploying them in practice requires powerful supercomputers equipped with large numbers of GPU coprocessors. For these systems to operate efficiently, the processors must exchange data as effectively as possible across relatively narrow and slow communication channels and specialized data buses.
Automating the Development of GPU Kernels
Modern AI models run primarily on graphics accelerators. However, general-purpose libraries often fail to deliver maximum performance, which means engineers frequently need to write custom code for each specific task. Developing high-performance GPU kernels manually is time-consuming and requires specialized expertise. Engineers must understand GPU memory models, efficient memory access patterns, backend limitations and how to quickly diagnose compile-time and runtime errors.

Developing such code is a labor-intensive process that requires highly skilled specialists. Engineers manually tune parallelization parameters, test multiple configurations and profile the results. This cycle can take days or even weeks, and experts in low-level optimization remain in short supply.
KernelEvo significantly automates this process. The system can explore different implementation variants using CUDA or Triton and propose optimal solutions for engineers, while automatically testing code and analyzing errors.

How It Works: Accelerating Core Operations
Instead of the traditional manual cycle – write, test and debug – KernelEvo launches an automated search loop: code generation, validation, error repair and iteration.
This approach accelerates key operations by roughly 1.5 to 2 times. Faster kernels shorten the time required to train models, automatically generate and optimize GPU code and reduce both the time and cost involved in developing AI algorithms. The framework can also be applied to optimize a wide range of computational workloads running on graphics processors.
In commercial environments, the performance of GPU kernels directly affects the economics of AI projects. A 1.5–2× speed improvement reduces training time, lowers spending on cloud infrastructure and allows companies to train larger models within the same budget. For organizations operating large computing clusters, such gains can translate into substantial cost savings.
The results of the project are available as open-source code, allowing developers to modify and adapt the system to their own tasks.

Efficiency Becomes a Global Priority
Reducing the cost of AI computation has become a priority for research teams worldwide. In February 2026, Russian researchers presented a library that doubled the speed of data exchange between GPUs – a capability previously associated mainly with major global companies such as Meta and AMD.
In 2025, a Russian-Chinese research team introduced an algorithm that enables standard consumer gaming GPUs to perform scientific computing tasks, reducing reliance on expensive professional hardware.
In December 2025, Google announced the TorchTPU project, aimed at optimizing AI workloads on the company’s own chips and reducing developers’ dependence on the NVIDIA ecosystem.
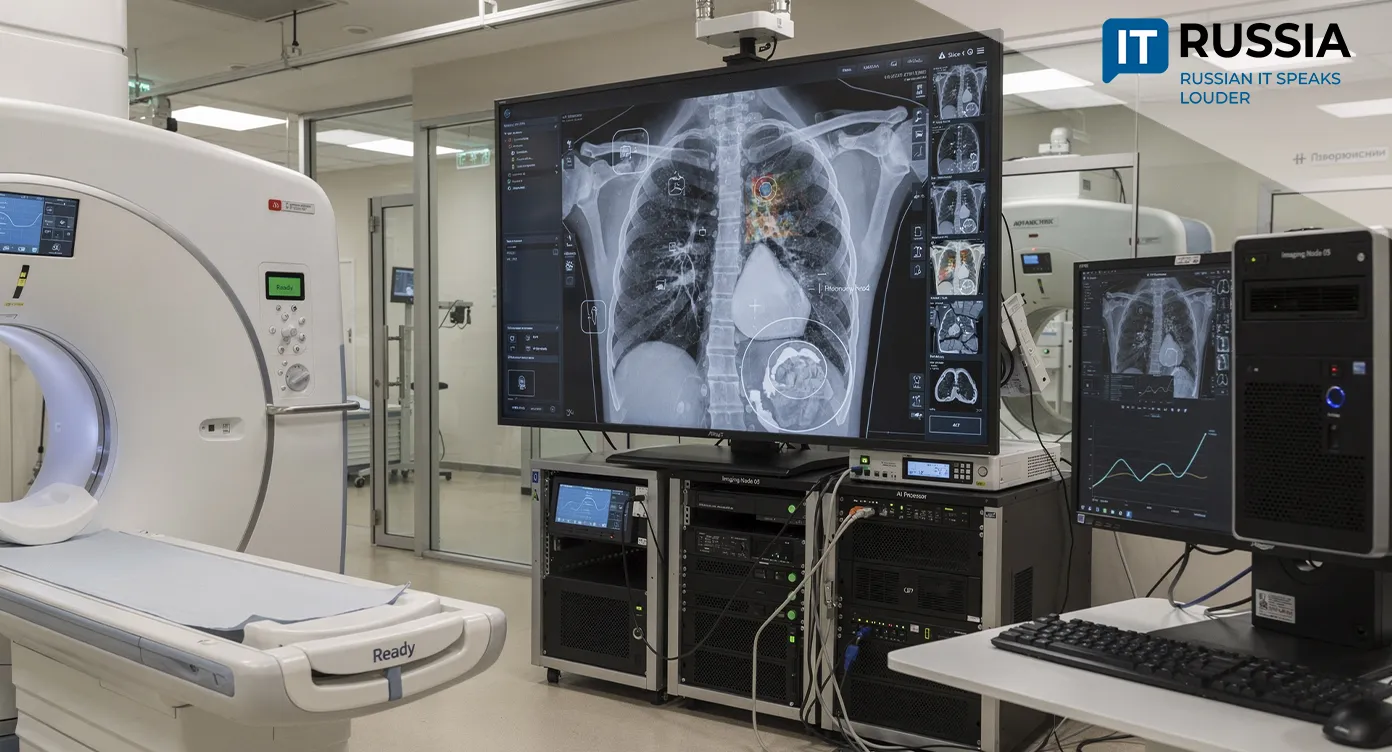
The rapid deployment of AI services – from voice assistants to medical diagnostics – lowers the cost of digital products, which ultimately benefits consumers.
For businesses, these advances make it possible to launch more sophisticated models within the same budget and bring products to market faster. At the national level, they strengthen technological sovereignty, expand expertise in AI infrastructure and reduce reliance on imported computing resources.

Building the Foundations for the Future
Experts predict that within the next three to five years automated optimization tools will become a standard component of neural network development. Without them, scaling AI systems becomes economically impractical. If KernelEvo gains strong community support, it could become part of the global open-source infrastructure that underpins modern AI development, similar to PyTorch or TensorFlow.
The AIRI project illustrates how seemingly invisible infrastructure work can lay the foundation for technological breakthroughs that ultimately affect everyday users. When code begins to write and improve itself, advanced technologies become more accessible and innovation moves closer to widespread adoption.